前言
为什么要写“从JS源码层面”呢,因为众所周知,node是由C++赋予了其控制操作系统的能力,因此node服务本身自然也是从C++层面开始启动,但本文目前暂不涉及C++相关内容,仅从JS代码层面来看下node服务的启动过程。主要是为了弄清主模块的加载、require导入模块的加载 以及preload模块的加载过程。三个文件的代码如下。
1 | // index.js |
通过node -r ./preload ./index.js即可得到如下输出
1 | preload |
一个比较直观的感受就是先加载的preload模块,然后在加载index.js时加载了load.js,最后执行完index.js。本文的测试以及调试的node源码版本均为v12.13.0
启动过程
runMain
故事的开始从internal/main/run_main_module.js文件开始
可以看到最开始先执行了prepareMainThreadExecution这个函数,做一些主线程的启动前的准备工作,其实preload模块的加载也在其中,但目前先按下不表,先分析主模块的加载过程,后面再来看这个preload模块的加载。
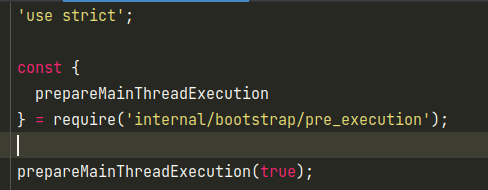
然后就是加载internal/modules/cjs/loader模块,这里主要是CJSModule的模块加载过程,高版本的node可以支持CommonJS和ESModule两种不同的语法类型,默认是选用CommonJS
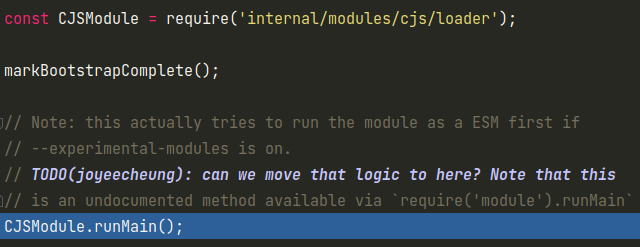
require('internal/modules/cjs/loader')模块中也执行了一部分代码,主要是一些Module类的初始化工作,以及一些函数定义,这里就先不细讲,主要来看下后面runMain函数中的内容。
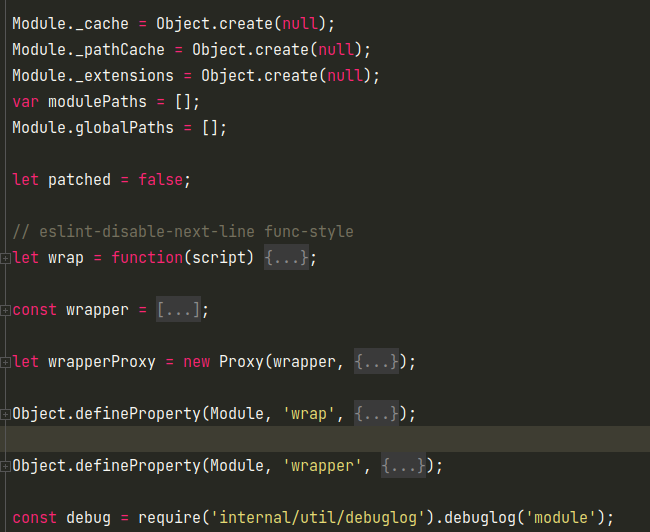
一开始是一些实验性模块的判断,对应--experimental-modules参数,用于开启一些特性
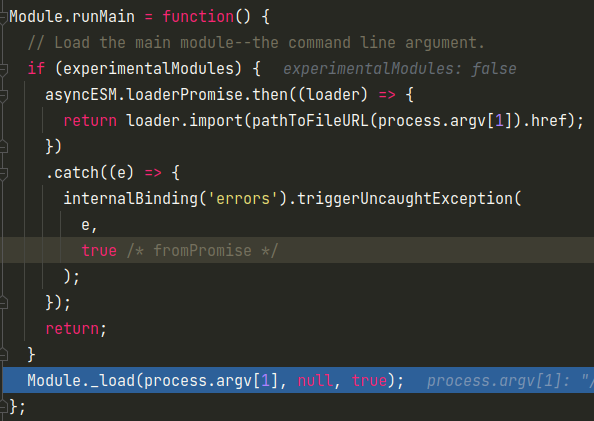
然后就是进入Module._load函数,这是一个递归函数,三个参数分别代表要加载的文件名、caller和是否是main文件。
其作用引用下注释中的话便比较容易懂了
Check the cache for the requested file.
- If a module already exists in the cache: return its exports object.
- If the module is native: call
NativeModule.prototype.compileForPublicLoader()and return the exports.- Otherwise, create a new module for the file and save it to the cache.
Then have it load the file contents before returning its exports
object.
就是如果Module的cache中已经存在对应的要加载的文件,则直接return exports对象。
1 | const filename = Module._resolveFilename(request, parent, isMain); |
如果模块是一个native模块,则调用NativeModule.prototype.compileForPublicLoader() 然后返回其exports。
1 | const mod = loadNativeModule(filename, request, experimentalModules); |
如果都不是,则就是正经首次加载模块的过程
如果main模块,则设置process.mainModule为当前模块名,并且设置module.id为.
1 | if (isMain) { |
然后会将module放入Module._cache中,并且在relativeResolveCache中缓存对应的文件名,并且如果最后load模块失败时会从缓存中删除对应的cache,从而保证了文件加载时不会产生无限递归的加载。
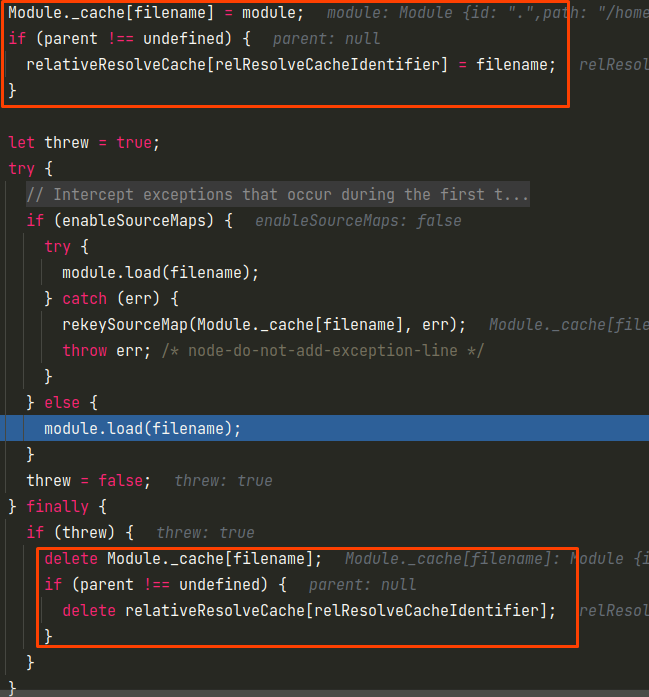
然后就是核心的module.load方法,根据文件名后缀调用不同的加载器
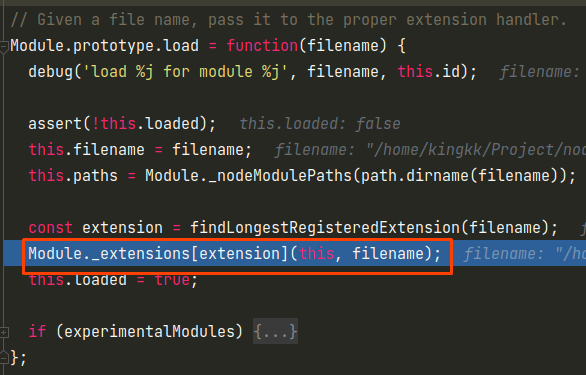
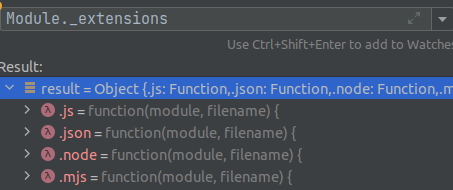
可以看到默认支持如下四个文件类型,这里主要来看下正常的.js的加载器
前面是一些future模块的特性,可以先跳过,然后就是读取文件内容,去掉BOM头,调用module._compile进行编译
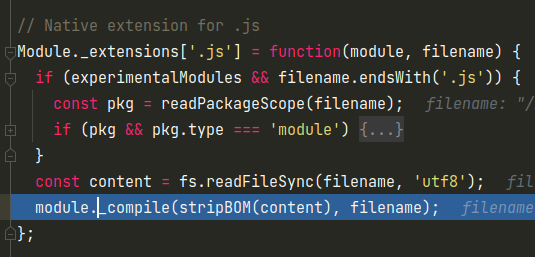
根据Module.prototype._compile的注释可以看出,我们编写的node代码会在一个对应的scope或者沙箱中运行,并且向其中暴露一些变量,如require、module、exports,我们也能知道这就是node中默认提供的一些内置函数。
Run the file contents in the correct scope or sandbox. Expose the correct helper variables (require, module, exports) to the file. Returns exception, if any.
前面是一些stripShebang和处理cache sourcemap相关的逻辑,可以先跳过。
如果是patched模式,则通过vm.runInThisContext在沙箱中运行代码。
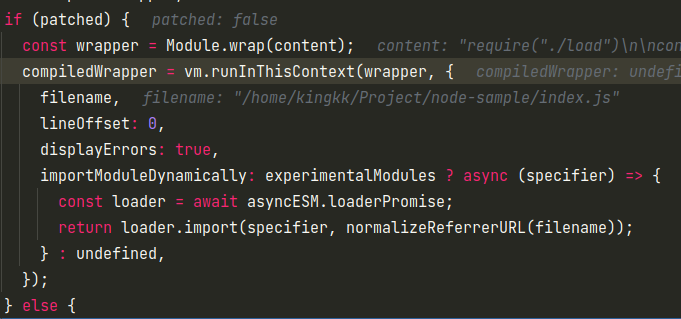
默认情况会进入else分支,则会创建一个函数,可以看到几个熟悉的内置变量名exports、require、module、__filename、__dirname。
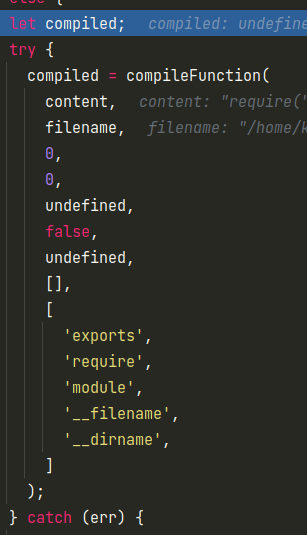
可以先不用管函数的具体生成方式,直接来看下生成的函数,即可知道其作用
1 | function (exports, require, module, __filename, __dirname) { |
可以看到其实做的仅是将我们的代码被被套入到了一个函数中,这也是node的js代码的实际运行方式。
然后其实就是获取到要传入这几个变量,调用这个生成的函数即可。dirname和filename就是对应的文件名没什么好说的,require变量默认情况就是module.require方法,exports和和module则分别就是this.exports和this了。
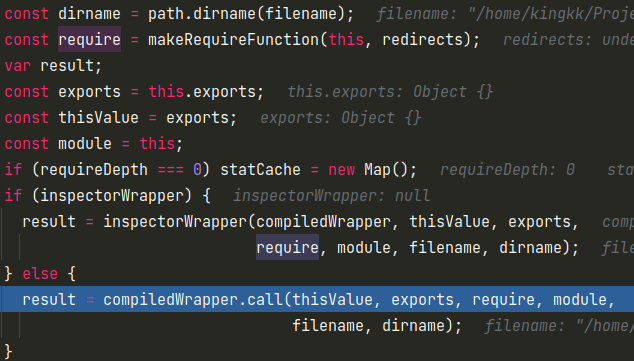
然后调用这个compiledWrapper.call就会执行我们编写的js文件了。
require module
然后我们的index.js中调用了require("./load"),之前说过,默认情况下require其实就是module.require函数。
简单的校验下传入的id,然后记录下require的深度,就会继续调用Module._load函数
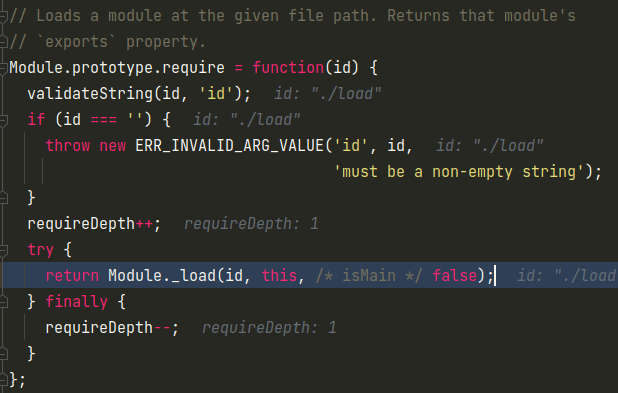
但是这回的区别在于传入的函数,parent原本为null,如今则是caller的模块,isMain也设置为了false。
这里parent为true与之前不同的便是这个缓存的机制,但其实也类似,便是如果Module._cache中存在了对应缓存则直接返回,否则和之前和load的逻辑一致,然后调用.js加载器,最后将源文件封装成一个compiledWrapper并执行。
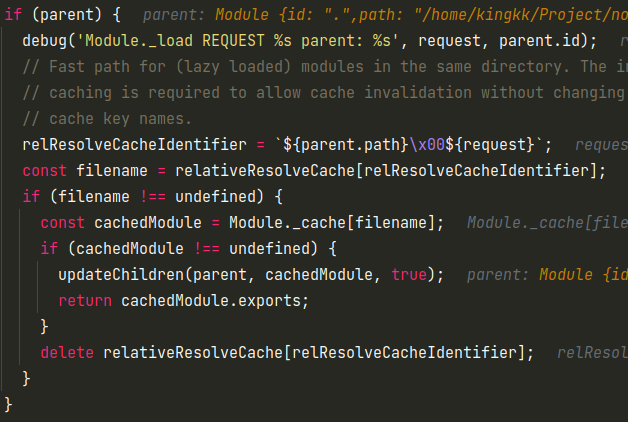
然后当还有require没加载过的模块时便会这样一致递归加载,直到当前模块所递归引用到的所有模块都加载完成之后依次退出,最后就完成了整个node文件的启动过程。
这整个过程都是同步的,后面执行的代码则是注册在事件循环中函数了。
preload
preload的加载过程则是在一开始的run_main_module的prepareMainThreadExecution中
其中做了许多init的东西,例如熟悉的inspector、自定义异常堆栈处理、CJS和EMS的模块初始化等,这里就不展开讲了。
然后就是loadPreloadModules函数的处理,根据-r参数的值,预处理对应的模块
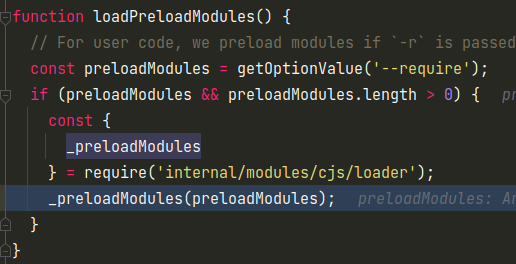
然后就到了Module._preloadModules模块中,需要注意的就是这里会设置parent为internal/preloadmodule,然后依次for循环-r参数的文件列表,进行require加载。
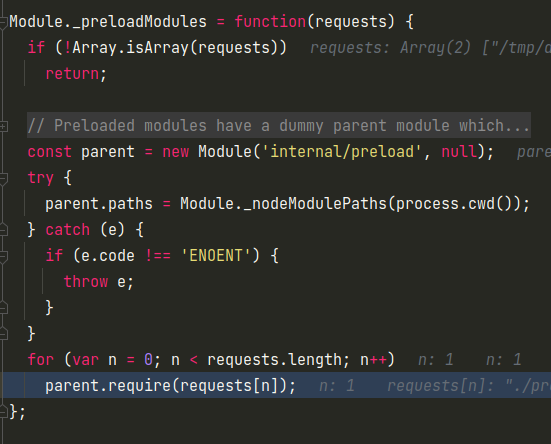
后面的过程就是Module.prototype.require和之前require模块的过程一样了。
这样我们就可以通过preload机制在主程序运行前进行一些预加载的处理机制。