Namespaces
namespace是linux提供的一种操作系统级别的资源隔离。
https://man7.org/linux/man-pages/man7/namespaces.7.html
命名空间是被不断完善加入到linux内核当中的,这里介绍几个常用的namespace(runc里会多一个Cgroup namespace)
- UTS(CLONE_NEWUTS):主要用于hostname的隔离
- User(CLONE_NEWUSER):User ID和group IDs的隔离
- PID(CLONE_NEWPID):进程id的隔离
- Mount(CLONE_NEWNS):挂载点的隔离
- Network(CLONE_NEWNET):网络设备、栈、端口等信息的隔离
- IPC(CLONE_NEWIPC):系统进程间通信的一些资源(System V IPC、 POSIX message queues )
go中通过设置cmd的SysProcAttr参数,即可设置进程的namespaces。
1 | cmd.SysProcAttr = &syscall.SysProcAttr{ |
通过这种方式我们也就可以创建一个命名空间隔离的进程,但是这里和docker的容器还是有一些差距,比如pid为1的进程不是本身,以及进程文件系统等信息。
以下以mydocker同时也是runc中做法为例。
1、先通过创建一个新的命名空间隔离的进程,运行/proc/self/exe(也就是当前程序本身)的init方法
2、init进程挂载自己的procfs到当前/proc目录,以及tmpfs当当前/dev目录
3、init进程通过系统调用syscall.Exec执行要运行的容器命令
挂载procfs让进程只能看到当前pid namespace的进程信息
挂载tmpfs到/dev目录让进程无法看到宿主机上挂载的设备信息
系统调用syscall.Exec让当前pid为1的进程为自己本身。
Cgroup
Control groups,控制组,也是linux内核级别的资源控制,这里的资源指的是内存、cpu核心数、cpu时间分片等资源。
https://man7.org/linux/man-pages/man7/cgroups.7.html
cgroup是一个层级的树状结构,linux以虚拟文件系统的方式对起进行展示。
通过cat /proc/self/mountinfo | grep memory就可以看到当前进程内存挂载的cgroup路径。(通常都是在/sys/fs/cgroup/目录下)

这里的memory就是一个cgroup的subsystem,默认有如下几个subsystem
- devices
- memory
- cpu
- cpuacct
- cpuset
- blkio
- perf_event
- freezer
- hugetlb
- pids
当我们要限制memory资源时,只需要在/sys/fs/cgroup/memory/docker/{container-id}/memory.limit_in_bytes文件中输入要限制的内存大小(如100m),然后在/sys/fs/cgroup/memory/docker/{container-id}/tasks中追加进程的pid即可。
tasks中的所有进程都会被限制成100m内存大小的限制。
因此在之前的init进程创建后,在对应的cgroup中设置对应的资源限制,以及当前进程的pid,即完成了容器的cgroup资源限制。
Image
其实通过docker pull下来的image都是一个个完整的文件系统,通过如下方式我们就可以获取一个busybox的镜像
1 | docker pull busybox |
这个busybox.tar中就是一个简易且完整的文件系统,只要将当前的rootfs切换到这个文件系统中,容器则有了自己的rootfs。
这里默认通过pivot_root这个系统调用进行rootfs的切换
https://man7.org/linux/man-pages/man2/pivot_root.2.html
通过如下方式就可以将我们的rootfs挂载到指定的文件系统中(例如busybox解压后的目录),容器也就有了自己独立的文件系统。
1 | // 重新挂载了一遍当前rootfs |
这里顺带提一嘴,我看了下runc的实现,默认也是通过pivot_root的方式。
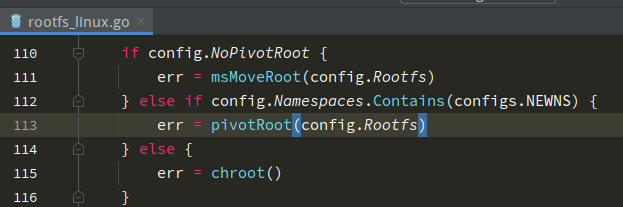
但是当rootfs是ramfs格式时,pivot_root是不支持的,需要通过如下方式进行切换根目录。
1 | mount(rootfs, "/", NULL, MS_MOVE, NULL); |
UnionFS
即联合文件系统,通俗来讲就是将几个只读目录和一个可写目录联合挂载到同一个目录,在联合挂载的目录上呈现的文件是那几个只读和一个可写目录的“叠加”状态。
linux有多种联合文件系统驱动,docker最初默认采用的是aufs,后续更改为overlay2,当然还支持一些例如 devicemapper 、 zfs 、vfs之类的文件驱动。
以aufs为例,通过如下方式即可将busybox目录作为只读目录,writeLayer做为可写目录挂载到mnt目录中。
1 | mount -t aufs -o dirs=./writerLayer:./busybox none ./mnt |
此时,在mnt上对文件进行修改操作时,会将修改后的内容拷贝一份到writeLayer目录中。
当对mnt上的文件进行删除操作时,writerLayer中会生成一个.wh.{filename} 的文件,标记filename文件被删除。
从而保证了容器上对文件的操作不会影响到镜像目录,而是只将增量保存在了writerLayer目录中,当容器被删除时,只要删除对应的writeLayer目录即可。
docker中这三个目录也分别有如下对应关系,只是通常一个容器镜像可能由多个layers只读层联合而成。
/var/lib/docker/aufs/mnt:docker实际挂载的目录/var/lib/docker/aufs/layers:只读镜像层/var/lib/docker/aufs/diff:可写层
顺带说一下volume数据卷,其实所谓数据卷其实也就是新生成了一个目录然后被联合挂载到了mnt中的指定目录,只是这个目录到时候会被保留下来。
Network
到目前为止,其实只差给容器“插上网线”,一个容器的基础功能其实就大差不离了。
这里介绍一下docker默认的桥接模式网络,主要会涉及veth、bridge、iptables这些概念。
首先需要创建一个bridge网桥
1 | la := netlink.NewLinkAttrs() |
然后设置这个bridge的ip(192.168.0.1),以及其路由表(192.168.0.0/24)
1 | ipNet, _ := netlink.ParseIPNet(rawIP) // 192.168.0.1/24 |
然后在宿主机设置如下iptables命令。即设置nat表,POSTROUTING链(用于转换源地址),当来源地址是192.168.0.0/24这个网段,并且不是从testbridge这个网卡中流出去的数据时(避免转发网段内通信),将源地址转换成宿主机的ip地址。
1 | iptables -t nat -A POSTROUTING -s 192.168.0.0/24 ! -o testbridge -j MASQUERADE |
此时查看ifconfig testbridge就可以看到生成的这个网桥设备
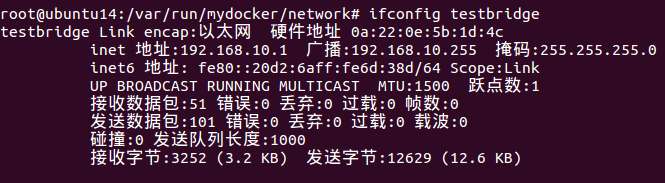
iptables -t nat -vnL POSTROUTING也可以看到testbridge的转发规则。

目前为止网桥设备已经准备好了,接下来就是为容器安上网卡
这里需要创建一对veth,一端连至bridge
1 | la := netlink.NewLinkAttrs() |
另一端配置成container的veth(虽然现在还没给容器安上),即容器的网卡
1 | endpoint.Device = netlink.Veth{ |
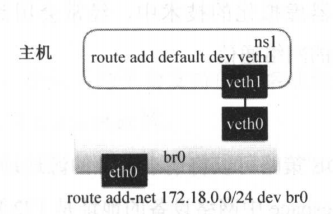
然后就是把另一端的veth设备放入容器的network namespace中,由于容器的network namespace是隔离的,因此启用veth的话需要先进入对应的命名空间。
顺便提下,这里setns操作只是改变当前线程的命名空间,但是go的调度模型可能会将goroutine调度到别的线程上,所以这里要通过runtime.LockOSThread()锁定下goroutine所在的线程。
进入容器的网络命名空间之后,就可以启用这张网卡,以及loopback本地环回网卡。最后设置路由表将本地所有流量都指向这个veth的网络设备。
目前为止,容器就拥有了和宿主机、bridge网段内容器、以及外网通信的能力。
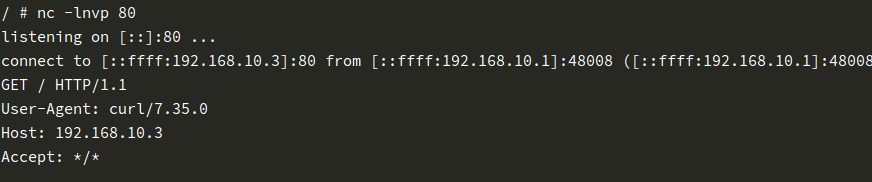
最后就是端口映射,我们只需要在本地的iptables中设置,将本地的80端口的tcp流量都转发到容器的80端口,即完成了本地端口和容器端口的映射。
1 | iptables -t nat -A PREROUTING -p tcp -m tcp --dport 80 -j DNAT --to-destination {container-ip}:80 |
此时监听容器中的80端口,即可就接收到发往宿主机80端口上的数据。
其他一些功能
daemon
即让容器进程独立运行,其实也比较简单,进程Start之后不要Wait它结束,等父进程退出之后,子进程就会变成孤儿进程,从而被init进程所接管。
但自己跑的时候 有个小坑,就是在goland中运行时,父进程退出了子进程也会跟着一起退出,换成在terminal中运行即可了。
exec
当容器进程以daemon方式运行时,如何再进入到容器内部呢。
通过setns这个系统调用就可以将当前线程放入到对应的namespace。
https://man7.org/linux/man-pages/man2/setns.2.html
还是之前那个go默认多进程+多线程调度模型的原因,导致运行时无法有确定的线程,这里runc中也采用了cgo的方式,通过cgo+__attribute__((constructor)),然后程序再最开始导入这个包时则会运行这个C代码,即在go环境初始完毕之前运行,从而保证了当前线程是一个确定的单线程。
https://golang.org/pkg/cmd/cgo/
然后就是在进入init进程前在环境变量中设置container的pid以及要exec的命令等信息。
进入init进程后,通过C的__attribute__((constructor))在go环境初始化前取出环境变量中的信息,然后setns(fd(/proc/container_pid/ns/*))进入container的命名空间,最后直接system调用要执行的命令即可。
不过这之后可能会出现go build编译不通过的情况,加入 -gcflags all=-N参数即可
stop
这个其实比较简单,因为容器在宿主机上看来只是一个进程而已,因此只要向进程发送SIGTERM信号,然后等待进程退出即可。
pipe
runc中的要执行的系统命令参数不是直接通过传参的方式传入init进程然后运行的,而是创建了一个pipe。
把这个writepipe保留在主进程中,启动init进程之后在往writepipe中写入要传入的命令。
而readpipe则通过如下方式设置为init进程文件描述符为3的文件(0、1、2分别已被标准输入、标准输出、错误输出预定)
1 | cmd.ExtraFiles = []*os.File{readPipe} |
然后init进程在执行完挂载的操作之后,再读取当前文件描述符为3的文件中的命令参数信息并执行。
References
https://github.com/xianlubird/mydocker
https://github.com/opencontainers/runc
https://github.com/opencontainers/runc/tree/master/libcontainer
https://man7.org/linux/man-pages/man7/namespaces.7.html
https://man7.org/linux/man-pages/man7/cgroups.7.html
https://man7.org/linux/man-pages/man2/setns.2.html
https://man7.org/linux/man-pages/man2/pivot_root.2.html
https://golang.org/pkg/cmd/cgo/