前言
本来2020年就写完了的,但最近发生了比较多事情,就一直也忘了更新,希望2021剩下的日子能好一些吧。
说实话一部分过程内的数据流分析算法现在也没搞太懂,凑活看吧,仅供参考。
AST & IR
通常来说,一个程序从源码(Source Code)到二进制程序/机器码(Machine Code)通常需要经过如下几个步骤
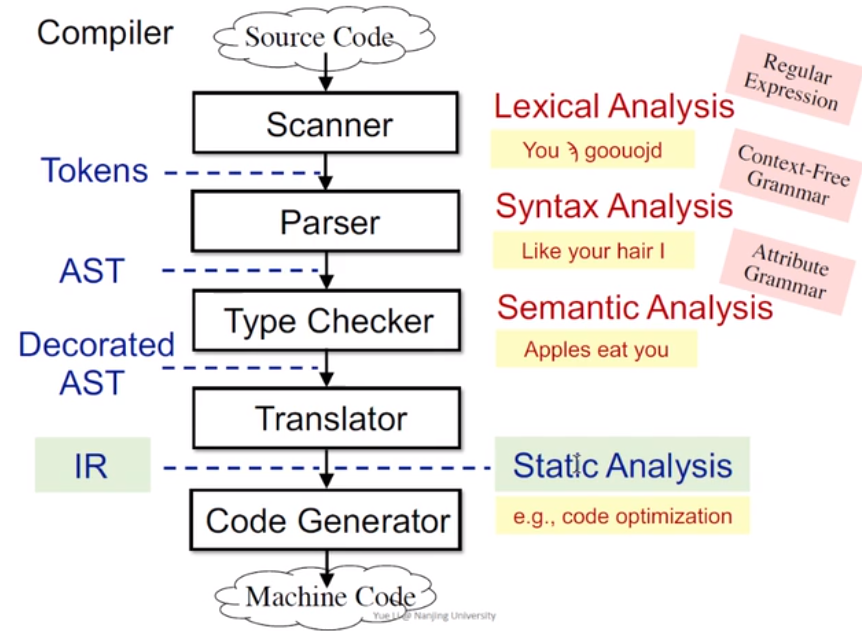
- 编译器在获取到源码之后,会先对源代码进行词法分析(Lexical Analysis),将源码分解成token。
- 之后对token流进行词法分析(Syntax Analysis),生成AST(Abstract Syntax Tree)抽象语法树。
- 然后对AST进行语义分析(Semantic Analysis),转换为IR(Intermediate Representation)中间表示形式
- 最后在IR的基础上进行一些优化(Optimization),最后生成可执行的二进制程序。
AST
- 在层级上更接近源码(Source Code),更高级(high-level)
- 适合于更快速的类型检查
- 语言相关
IR
- 在层级上更接近机器码(Machine Code),更低级(low-level)
- 更通用,适合静态程序分析
- 语言无关
三地址码
一种常用的IR,每一条语句最多有三个地址
- i = i + 1
- t1 = a[i]
- if(t1 < v) goto 1
SSA
静态单赋值(Static Single Assignment),一种三地址码
即每个变量都只被赋值一次

Def-Use
给定变量x,如果结点A可能改变x的值,结点B可能使用结点A改变后的x的值,结点A和结点B存在Def-Use关系
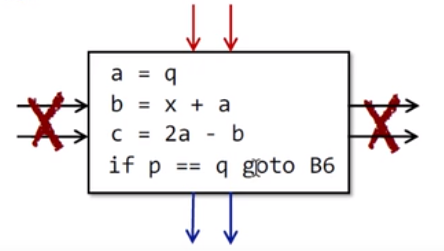
Basic Block
简单说就是一个最基础的代码块,它不会被拆分,只有一个出口和入口,总是从入口 → 出口顺序执行。
算法
对于一个函数,通常需要将其分割为几个basic block,简要算法如下
1、找到所有leaders
对于所有分支点(branch),比如一些return、goto之类的语句
找到它要跳转到的语句,如图中则是(3)、(7)(12)
以及其下一条语句,图中为(5)、(11)、(12)
外加一条程序入口的语句(1)
这些就是该函数的leaders。

2、以leader为分割点将程序进行分割
因此程序就被分成了
- B1 {(1),(2)}
- B2 {(3),(4)}
- B3 {(5),(6)}
- B4 {(7),(8),(9),(10)}
- B5 {(11)}
- B6 {(12)}
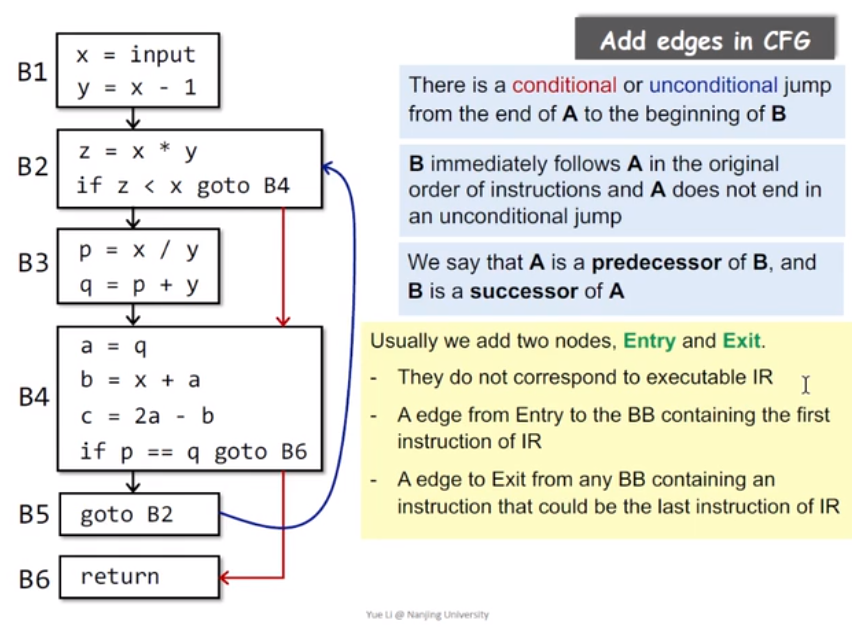
Control Flow Graph
控制流图,在basic block的基础上构建控制流图也相对比较简单。
- 对所有最后一条语句不是跳转的basic block与其相邻的basic block相连
- 对有最后一条语句是有条件跳转的basic block,与其相邻的basic block和其跳转的basic block相连
- 对于最后一条语句是无条件跳转的basic block,直接将其于跳转的basic block相连
此外,对于控制流图来说还有两个概念Entry 和 Exit
- Entry即程序的入口,通常是第一个语句,一般来说只有一个
- Exit则是程序的出口,通常是return之类的语句,可能会有多个
数据流分析(过程内)
到达定值分析
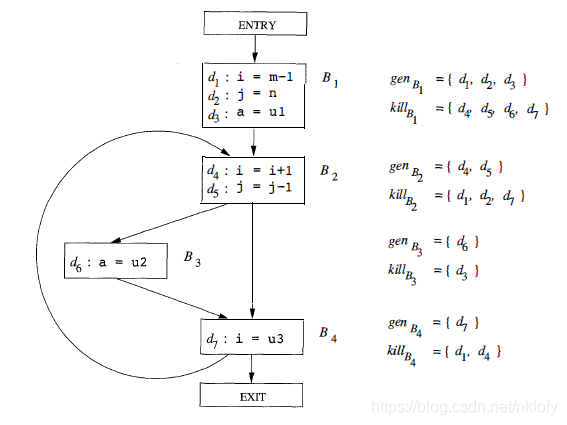
如有上图这样一个函数,要去分析变量x在某个位置可能的值。
定义:
- gen:该basic block中赋值语句产生新值的语句
- kill:其他basic block中重新定义新值的语句
- In[B]:该basic block初始的状态
- Out[B]:该basic block执行结束的状态
则有如下伪代码:
1 | Init: |
最开始将程序Entry和各个block的Out都设置为空集
然后计算各个block的gen和kill
以B1为例,三条语句分别定义了i、j、a,因此gen(b1) = {d1, d2, d3}
i、j、a同时也在其他语句d4、d5、d6、d7中被重新赋值,因此kill(b1) = {d4, d5, d6, d7}
其余block依次计算即可获得所有block的gen和kill
然后通过loops中的迭代的算法,计算每个block的状态
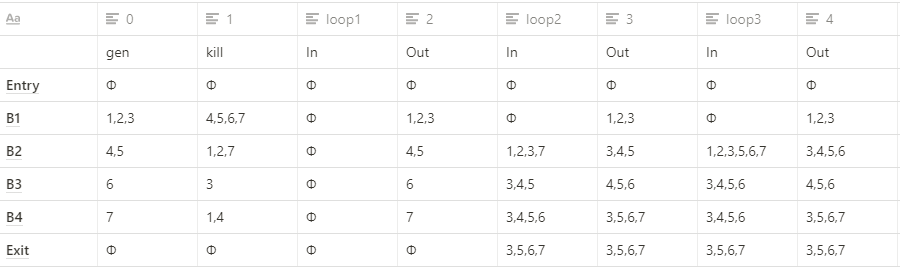
第一轮的In都是初始前驱的Out,因此都是空集。Out的话根据Out[B] = In[B] + gen - kill即可算出
第二轮时,In(b1)是Out(entry),也是空集,Out(b1)计算即可得。In(b2)则是前驱Out(b1)+Out(b4)的结果,也就是第一轮b4的Out和第二轮b1的Out的交集,即{1,2,3,7}
依次迭代,知道loop3结束时,Exit的结果和loop2时的一致,则表示达到了一个不动点。
则也意味着{d3, d5, d6, d7}这几条语句的赋值能传递到exit。
活跃变量分析
这个分析是为了知道p1处x的值,是否在路径p2上被使用。其实就是分析Def-Use关系
此时定义
- def:变量在当前block中定值前未被使用
- use:变量在当前block中使用前未被定值
其余In(B)和Out(b)的定义不变
则有In[B] = use + (Out[B] - def)
因此伪代码为
1 | Init: |
可以看到这里传播的方向是和前面到达定值分析是相反的
并且其实把def看作gen,use看作kill,两个关系式是能相互对应起来的
总结
因此类似的数据流分析都能通过如上的框架进行分析
1、每个节点的数据流值分别对应为In[S]和Out[S],如上的节点单位则是一个block
2、传递函数(transfer function)定义了In[S]和Out[S]的关系
- 前向(forward)传递:Out[S] = fs(In[S])
- 后向(backward)传递:In[S] = fb(Out[S])
一个数据流分析框架可以被表示为一个三元组(D, V, ∧,F)
- D:数据流分析的方向
- V:数据流单位,对于定值分析来说则是定值语句
- ∧:交汇运算符,可以是交集或并集
- F:一组传递函数
然后这个算法是可收敛的么?是否会一致递归下去?
结论是可收敛的,复杂度是O(n^2)。为什么?超纲了,下一题
Worklist Algorithm(worklist算法)
迭代算法的优化
1 | OUT[entry] =∅; |
话说ASM的Analyzer类就实现了这个算法,可以进行一些变量类型的分析。
Call Graph
调用图,是一个描述从调用点(call site)到被调函数(callee)的边的集合
A call graph is a set of call edges from call-sites to their target methods (callees)
常用算法
以Java为例,由于其OOP的多态特性,导致其实际调用的函数只有在运行时才能确定
因此静态的方式只能尽可能的分析其可能调用到的callee,从而来构造对应Call Graph
- Class hierarchy analysis(CHA)通过类继承关系去构造调用图
- Rapid type analysis(RTA)
- Variable type analysis(VTA)
- Pointer analysis(k-CFA)通过分析可能的引用去构造调用图
从上至下依次精度越高,但速度越慢。
CHA(Class Hierarchy Analysis)
这种方式只考虑声明类型,并不会去判断实例的具体类型。
因此通过类之间的继承关系,找到被重写的函数,即可找到所有可能被调用的函数。
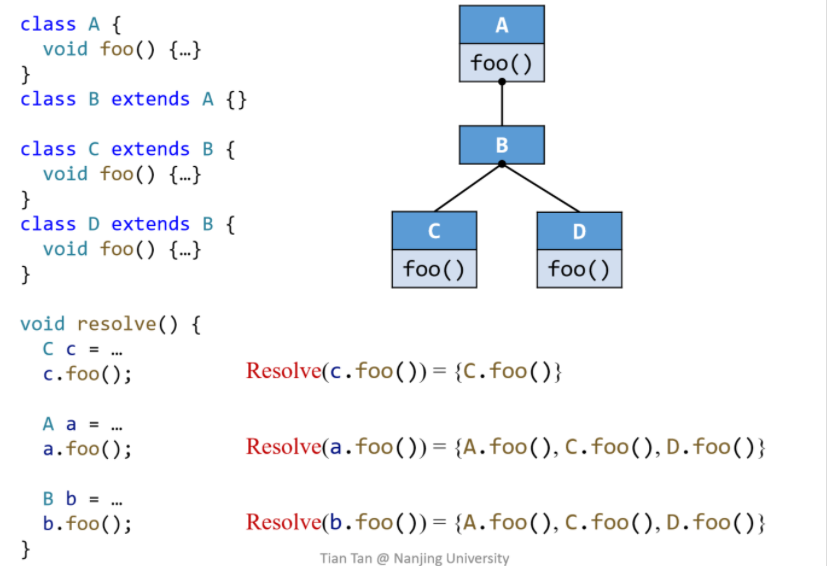
这种方式相对比较快,不会进行上下文关联的分析
因此当继承重写关系比较复杂时,生成的Call Graph可能会很庞大
Pointer Analysis
指针分析,基础的指针分析用于计算指针指向的内存。面向对象的指针分析用于计算指针指向哪个对象。
A fundamental static analysis, computes which memory locations a pointer can point to.
For object-oriented programs, computes which objects a pointer (variable or field) can point to.
这里的主要目的则是为了通过指针分析获取到当前实例具体指向的类,从而获取到更精确的Call Graph,不过这样相对来说成本也变高了。
你问我算法?超纲了 🤧
Datalog
编程范式
Imperative(指令式)语言:Java、C/C++,展示详细的实现细节。
Declarative(声明式)语言:SQL,屏蔽细节,可读性较高。
Datalog则是一种声明式语言,早期用于数据库查询,而如今已经被用于程序分析、大数据、云计算等多个领域。
优点再与语言的可读性比较强,编写相对接单。但其性能完全取决于其实现引擎,并且表达优先,不是一个图灵完备的语言。
predicate
谓词(predicate)类似于一个断言,描述符合当前要求数据的事实
最熟悉的应该就是CodeQL的,它也是采用声明式的语言来进行数据查询。
CodeQL主要得以于其优秀的查询引擎、在声明式语言中新引入了OOP的编程方式,以及大量的ql基础库中的高质量的轮子,从而使得一个污点分析的查询变得比常规污点分析简单很多。
但是如果没有那些轮子,这个引擎以及基础库的工作是不是会比指令式的工作要大得多?
Datalog作为新兴的程序分析模型,让我们以另一种视角去看待程序分析。
其作用主要在于简化查询的方式,但不会比指令式提供更多的信息源,因此个人对于网上一些仿照CodeQL建数据库的行为一直存疑,不过毕竟是种新视角,最近QL写惯了也慢慢适应了…
References
https://pascal-group.bitbucket.io/teaching.html
https://www.bilibili.com/video/av91858985
https://anemone.top/pl-静态程序分析课程笔记(简介)/
https://anemone.top/pl-静态程序分析课程笔记(过程间分析)/
https://anemone.top/pl-静态程序分析课程笔记(数据流分析-理论基础)/
https://anemone.top/pl-静态程序分析课程笔记(Datalog)/
https://xiongyingfei.github.io/SA/2019/05_static_single_assignment.pdf
http://www.cse.unsw.edu.au/~jingling/papers/ecoop14.pdf
https://zh.wikipedia.org/wiki/指令式編程
https://zh.wikipedia.org/wiki/宣告式編程
https://help.semmle.com/QL/learn-ql/introduction-to-ql.html
https://chengxiao19961022.github.io/2019/03/04/静态数据流分析/