前言 之前在实习的时候在先知上看到 @threedr3am 师傅在先知上发了两篇关于gadgetinspector分析的文章 https://xz.aliyun.com/t/7058 ,确实写的很好。关于gadgetinspector这款工具之前就有注意到过,但是没有具体去看。
由于之前有过想法做类似的东西,所以对这个也很感兴趣,但是由于一些子/父类、接口/实现类之间的处理有些头疼,于是做了个简易版,挖了个新的gadget之后便没后文了。正好最近疫情严重,在家都快呆发霉了,便想来看下这款工具是如何做这些处理操作的。
整体概览 整个程序的入口是GadgetInspector类,大致看一下main函数以及跑一下整个程序,就可以看到几个比较关键的类,以及以文件形式存储在本地的.dat备份文件。
MethodDiscovery 用以收集类/方法以及继承/实现关系,分别对应classes.dat、methods.dat、inheritanceMap.datPassthroughDiscovery 用以发现函数返回值与传参之间的污点关系,对应passthrough.datCallGraphDiscovery 用以发现函数之间的调用关系,对应callgraph.datSourceDiscovery 用以发现所有source点,对应sources.datGadgetChainDiscovery 前面的工作都算信息搜集的步骤,有了前面的信息之后,就可以真正开始挖掘gadget了
启动入口 一开始的工作其实很简单,主要就是参数的绑定和一些日志之类的配置
一开始就是参数判断,输出用法,然后配置日志信息
1 2 3 4 5 6 7 if (args.length == 0 ) { printUsage(); System.exit(1 ); } configureLogging();
之后就是根据命令行传参设置resume、config、boot几个参数,分别对应是否删除bat文件,gadget类型,和是否是springboot的jar包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 boolean resume = false ;GIConfig config = ConfigRepository.getConfig("jserial" ); boolean boot = false ;int argIndex = 0 ;while (argIndex < args.length) { String arg = args[argIndex]; if (!arg.startsWith("--" )) { break ; } if (arg.equals("--resume" )) { resume = true ; } else if (arg.equals("--config" )) { config = ConfigRepository.getConfig(args[++argIndex]); if (config == null ) { throw new IllegalArgumentException("Invalid config name: " + args[argIndex]); } giConfig = config; } else if (arg.equals("--boot" )) { boot = true ; } else { throw new IllegalArgumentException("Unexpected argument: " + arg); } argIndex += 1 ; }
之后根据普通jar包、spring-boot jar包、war包载入对应字节码,返回对应的URLClassloader。具体细节就不跟进看了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 final ClassLoader classLoader;if (args.length == argIndex + 1 && args[argIndex].toLowerCase().endsWith(".war" )) { Path path = Paths.get(args[argIndex]); LOGGER.info("Using WAR classpath: " + path); classLoader = Util.getWarClassLoader(path); } else if (args.length == argIndex + 1 && args[argIndex].toLowerCase().endsWith(".jar" ) && boot) { Path path = Paths.get(args[argIndex]); LOGGER.info("Using JAR classpath: " + path); classLoader = Util.getJarAndLibClassLoader(path); } else { final Path[] jarPaths = new Path[args.length - argIndex]; for (int i = 0 ; i < args.length - argIndex; i++) { Path path = Paths.get(args[argIndex + i]).toAbsolutePath(); if (!Files.exists(path)) { throw new IllegalArgumentException("Invalid jar path: " + path); } jarPaths[i] = path; } LOGGER.info("Using classpath: " + Arrays.toString(jarPaths)); classLoader = Util.getJarClassLoader(jarPaths); }
之后自己封装了一个ClassResourceEnumeratorclassloader,具有两个方法
getRuntimeClasses获取rt.jar的所有classgetAllClasses获取rt.jar以及classLoader加载的class
1 final ClassResourceEnumerator classResourceEnumerator = new ClassResourceEnumerator(classLoader);
之后就是根据resume参数来决定是否删除之前留下的备份文件,相当于一个缓存的作用,需要时直接从备份文件中取相应信息即可。
1 2 3 4 5 6 7 8 9 10 11 12 if (!resume) { LOGGER.info("Deleting stale data..." ); for (String datFile : Arrays.asList("classes.dat" , "methods.dat" , "inheritanceMap.dat" , "passthrough.dat" , "callgraph.dat" , "sources.dat" , "methodimpl.dat" )) { final Path path = Paths.get(datFile); if (Files.exists(path)) { Files.delete(path); } } }
之后就能看到分出了5个明显的block,也分别对应了之前整体概览里提到的五个类所做的事情。
前四个主要都是信息搜集的工作,也正是要处理好这些数据流、方法重写等问题,才能更好也更全面的找gadget。
MethodDiscovery 1 2 3 4 5 6 7 8 if (!Files.exists(Paths.get("classes.dat" )) || !Files.exists(Paths.get("methods.dat" )) || !Files.exists(Paths.get("inheritanceMap.dat" ))) { LOGGER.info("Running method discovery..." ); MethodDiscovery methodDiscovery = new MethodDiscovery(); methodDiscovery.discover(classResourceEnumerator); methodDiscovery.save(); }
主要看discover方法,是如何获取类、方法以及继承/实现信息的。
discover 由于提供的是字节码信息,则需要一个字节码操作工具,这里用的是asm,算是一个比较底层且全的字节码操作库,由于个人不是特别熟,只能浅显的看一下。
看到在discover方法中获取了所有的类,并通过MethodDiscoveryClassVisitor去记录类和类方法信息。
1 2 3 4 5 6 7 8 9 10 11 for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) { try (InputStream in = classResource.getInputStream()) { ClassReader cr = new ClassReader(in); try { cr.accept(new MethodDiscoveryClassVisitor(), ClassReader.EXPAND_FRAMES); } catch (Exception e) { LOGGER.error("Exception analyzing: " + classResource.getName(), e); } } }
跟进可以看到MethodDiscoveryClassVisitor继承了ClassVisitor,他会以一种观察者模式的方式去扫描所有信息。
1 private class MethodDiscoveryClassVisitor extends ClassVisitor
MethodDiscoveryClassVisitor通过重载了类的一些方法之后,就可以在扫描不同部分信息时,增加一些自己的操作。
这里最先被调用的是visit方法,里面会传入版本号,类名,签名,父类名,实现接口等信息,这这里主要对他们做了记录,并保存在自己的成员变量中
1 2 3 4 5 6 7 8 9 10 11 12 @Override public void visit ( int version, int access, String name, String signature, String superName, String[]interfaces) this .name = name; this .superName = superName; this .interfaces = interfaces; this .isInterface = (access & Opcodes.ACC_INTERFACE) != 0 ; this .members = new ArrayList<>(); this .classHandle = new ClassReference.Handle(name); annotations = new HashSet<>(); super .visit(version, access, name, signature, superName, interfaces); }
然后访问到注解信息时,也会将注解信息记录在成员变量中
1 2 3 4 5 @Override public AnnotationVisitor visitAnnotation (String descriptor, boolean visible) annotations.add(descriptor); return super .visitAnnotation(descriptor, visible); }
访问成员变量时,记录修饰符,变量名信息,并封装成定义好的ClassReference
访问时会跳过静态变量,因为这一部分变量应该是全局性的,无法通过反序列化等方式控制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public FieldVisitor visitField (int access, String name, String desc, String signature, Object value) if ((access & Opcodes.ACC_STATIC) == 0 ) { Type type = Type.getType(desc); String typeName; if (type.getSort() == Type.OBJECT || type.getSort() == Type.ARRAY) { typeName = type.getInternalName(); } else { typeName = type.getDescriptor(); } members.add(new ClassReference.Member(name, access, new ClassReference.Handle(typeName))); } return super .visitField(access, name, desc, signature, value); }
访问方法时也是同理,记录类名、方法名、签名、以及是否是静态等信息封装成MethodReference的形式存储
1 2 3 4 5 6 7 8 9 10 11 @Override public MethodVisitor visitMethod (int access, String name, String desc, String signature, String[] exceptions) boolean isStatic = (access & Opcodes.ACC_STATIC) != 0 ; discoveredMethods.add(new MethodReference( classHandle, name, desc, isStatic)); return super .visitMethod(access, name, desc, signature, exceptions); }
当一个类访问结束时就会调用visitEnd,做一些类似析构函数的工作
这里就是封装成ClassReference的方式存储类信息
1 2 3 4 5 6 7 8 9 10 11 12 13 @Override public void visitEnd () ClassReference classReference = new ClassReference( name, superName, interfaces, isInterface, members.toArray(new ClassReference.Member[members.size()]), annotations); discoveredClasses.add(classReference); super .visitEnd(); }
当这些工作都做完之后,类信息/方法信息/字段信息等就算搜集完成了
save 之后就是比简单的save工作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public void save () throws IOException DataLoader.saveData(Paths.get("classes.dat" ), new ClassReference.Factory(), discoveredClasses); DataLoader.saveData(Paths.get("methods.dat" ), new MethodReference.Factory(), discoveredMethods); Map<ClassReference.Handle, ClassReference> classMap = new HashMap<>(); for (ClassReference clazz : discoveredClasses) { classMap.put(clazz.getHandle(), clazz); } InheritanceDeriver.derive(classMap).save(); }
ClassReference.Factory和MethodReference.Factory()都定义了对应的存储方式
classes.dat 类名 | 父类名 | 所有接口 | 是否是接口 | 成员变量
methods.dat 类名 | 方法名 | 方法描述信息 | 是否是静态方法
然后在InheritanceDeriver.derive(classMap)根据类信息,就可以获取到所有的继承/实现关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static InheritanceMap derive (Map<ClassReference.Handle, ClassReference> classMap) LOGGER.debug("Calculating inheritance for " + (classMap.size()) + " classes..." ); Map<ClassReference.Handle, Set<ClassReference.Handle>> implicitInheritance = new HashMap<>(); for (ClassReference classReference : classMap.values()) { if (implicitInheritance.containsKey(classReference.getHandle())) { throw new IllegalStateException("Already derived implicit classes for " + classReference.getName()); } Set<ClassReference.Handle> allParents = new HashSet<>(); getAllParents(classReference, classMap, allParents); implicitInheritance.put(classReference.getHandle(), allParents); } return new InheritanceMap(implicitInheritance); }
可以看到遍历了所有的类,然后再通过getAllParents以递归的方式获取所有的父类和实现类
然后最后翻转转换成父类 -> [子类1、子类2...]的对应关系
然后保存到inheritanceMap.dat中
这样,类信息/方法信息/继承实现关系的信息搜集就完成了。
PassthroughDiscovery 主要用以发现函数返回值与传参之间的污点关系,个人感觉是工作量最大的一个部分,因为不仅仅是信息搜集,还要做污点的信息判断,以及方法间的变量关联。
1 2 3 4 5 6 if (!Files.exists(Paths.get("passthrough.dat" ))) { LOGGER.info("Analyzing methods for passthrough dataflow..." ); PassthroughDiscovery passthroughDiscovery = new PassthroughDiscovery(); passthroughDiscovery.discover(classResourceEnumerator, config); passthroughDiscovery.save(); }
和之前的过程类似,也是分为discover发现和save保存的两个过程。
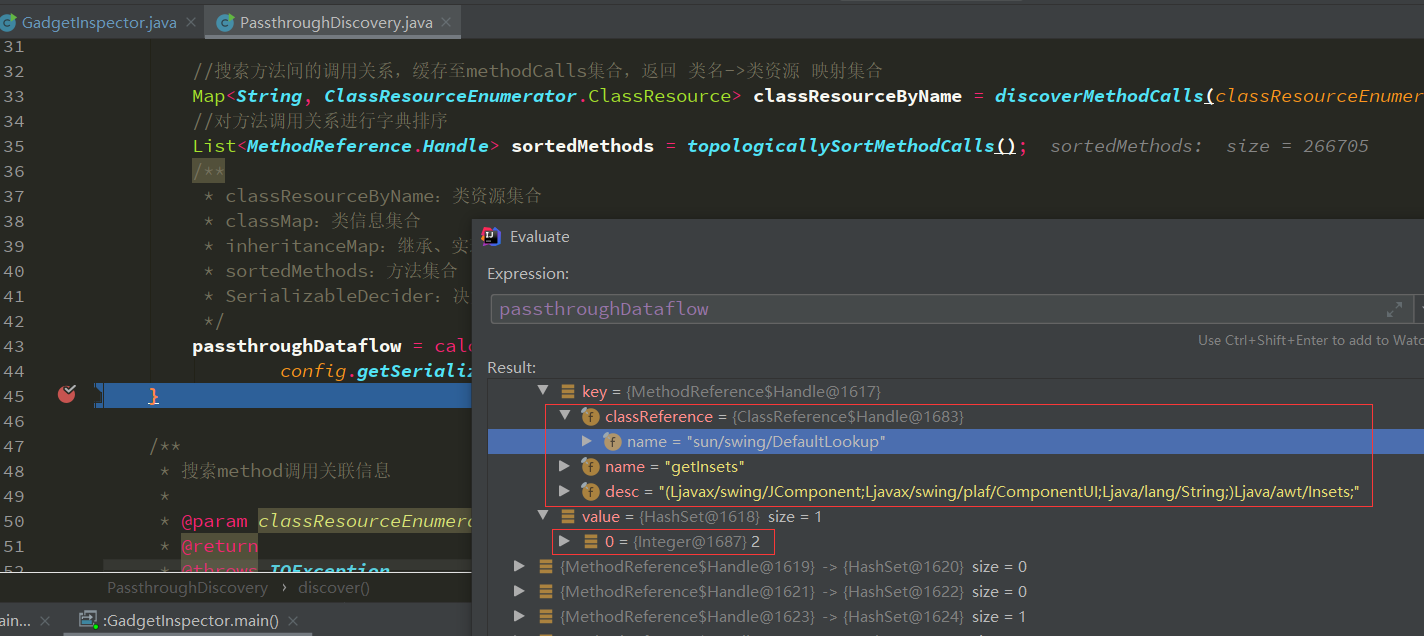
discover 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods(); Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses(); InheritanceMap inheritanceMap = InheritanceMap.load(); Map<String, ClassResourceEnumerator.ClassResource> classResourceByName = discoverMethodCalls(classResourceEnumerator); List<MethodReference.Handle> sortedMethods = topologicallySortMethodCalls(); passthroughDataflow = calculatePassthroughDataflow(classResourceByName, classMap, inheritanceMap, sortedMethods, config.getSerializableDecider(methodMap, inheritanceMap));
一开始就是将MethodDiscovery收集到的信息加载进来以供分析。
discoverMethodCalls
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private Map<String, ClassResourceEnumerator.ClassResource> discoverMethodCalls(final ClassResourceEnumerator classResourceEnumerator) throws IOException { Map<String, ClassResourceEnumerator.ClassResource> classResourcesByName = new HashMap<>(); for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) { try (InputStream in = classResource.getInputStream()) { ClassReader cr = new ClassReader(in); try { MethodCallDiscoveryClassVisitor visitor = new MethodCallDiscoveryClassVisitor(Opcodes.ASM6); cr.accept(visitor, ClassReader.EXPAND_FRAMES); classResourcesByName.put(visitor.getName(), classResource); } catch (Exception e) { LOGGER.error("Error analyzing: " + classResource.getName(), e); } } } return classResourcesByName; }
和之前一样,重载了ClassVisitor,重点看重载的visitMethod方法
1 2 3 4 5 6 7 8 9 10 @Override public MethodVisitor visitMethod (int access, String name, String desc, String signature, String[] exceptions) MethodVisitor mv = super .visitMethod(access, name, desc, signature, exceptions); MethodCallDiscoveryMethodVisitor modelGeneratorMethodVisitor = new MethodCallDiscoveryMethodVisitor( api, mv, this .name, name, desc); return new JSRInlinerAdapter(modelGeneratorMethodVisitor, access, name, desc, signature, exceptions); }
这里对每个method进行观察
MethodCallDiscoveryMethodVisitor重载了MethodVisitor,可以看出是一个方法观察者
和ClassVisitor类似,可以通过重写方法,来在观察至指定位置时添加自定义的功能。
在初始化的时候,往methodCalls中添加一个method -> calledMethods的键值对,也就是获取方法和方法中调用的方法的对应值
1 2 3 4 5 6 7 public MethodCallDiscoveryMethodVisitor (final int api, final MethodVisitor mv, final String owner, String name, String desc) super (api, mv); this .calledMethods = new HashSet<>(); methodCalls.put(new MethodReference.Handle(new ClassReference.Handle(owner), name, desc), calledMethods); }
真正收集方法中调用的方法的部分则是在visitMethodInsn,这部分则是在method中调用其他方法时,会被触发的逻辑
里面有被调用方法的方法名、所属类、函数前面等信息,只要将这些信息存放到calledMethods中即可
1 2 3 4 5 @Override public void visitMethodInsn (int opcode, String owner, String name, String desc, boolean itf) calledMethods.add(new MethodReference.Handle(new ClassReference.Handle(owner), name, desc)); super .visitMethodInsn(opcode, owner, name, desc, itf); }
到这里,方法和方法中调用的函数的对应关系都获取到了
最后discoverMethodCalls返回了类名和资源文件的对应关系。
再后面就是对methods进行了拓扑排序
1 List<MethodReference.Handle> sortedMethods = topologicallySortMethodCalls();
这里说实话一开始我怎么都看不懂这里的排序是干什么用的,为什么返回的是一个List,排序的意义又是什么呢?
最后百度了下发现吃了没文化的亏。 https://baike.baidu.com/item/%E6%8B%93%E6%89%91%E6%8E%92%E5%BA%8F/5223807
拓扑排序常用来确定一个依赖关系集中,事物发生的顺序。例如,在日常工作中,可能会将项目拆分成A、B、C、D四个子部分来完成,但A依赖于B和D,C依赖于D。为了计算这个项目进行的顺序,可对这个关系集进行拓扑排序,得出一个线性的序列,则排在前面的任务就是需要先完成的任务。
注意:这里得到的排序并不是唯一的!就好像你早上穿衣服可以先穿上衣也可以先穿裤子,只要里面的衣服在外面的衣服之前穿就行。
因为我们判断一个函数是否可传递污点,主要是判断传参和返回值之间的关系,当中间经过一些其他函数时,就要跟进去判断那个函数的污点传递性。为了避免多次判断一些基础函数的传递性时,就可以对其进行拓扑排序。先将基础函数的传递性判断完毕,再判断上层调用函数的传递性,避免不必要的多次判断。(当然应该也可以用缓存的方式,缓存下判断过程中判断过的函数)
由于普通的拓扑排序是建立于有向无环图的基础上的,但是代码间的调用自然会呈现环状。这里对其做了一些处理,感觉seebug的这篇文章对这部分做了很形象的解释,估计一看就懂。 https://paper.seebug.org/1034/#step2-passthrough
至于具体的代码也就不具体分析了,也就是前面形象解释的具体实现。
之后回到检测的逻辑,就可以开始真正的对每个函数进行污点传递性的判断了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 final Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = new HashMap<>();for (MethodReference.Handle method : sortedMethods) { if (method.getName().equals("<clinit>" )) { continue ; } ClassResourceEnumerator.ClassResource classResource = classResourceByName.get(method.getClassReference().getName()); try (InputStream inputStream = classResource.getInputStream()) { ClassReader cr = new ClassReader(inputStream); try { PassthroughDataflowClassVisitor cv = new PassthroughDataflowClassVisitor(classMap, inheritanceMap, passthroughDataflow, serializableDecider, Opcodes.ASM6, method); cr.accept(cv, ClassReader.EXPAND_FRAMES); passthroughDataflow.put(method, cv.getReturnTaint()); } catch (Exception e) { LOGGER.error("Exception analyzing " + method.getClassReference().getName(), e); } } catch (IOException e) { LOGGER.error("Unable to analyze " + method.getClassReference().getName(), e); } } return passthroughDataflow;
根据数据类型就可以看出passthroughDataflow获取到的应该是一个函数与会影响返回值的参数index
遍历之前拓扑排序后的函数列表,并且跳过静态初始化方法,和之前一样重载了一个类观察者
重写了visitMethod方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Override public MethodVisitor visitMethod (int access, String name, String desc, String signature, String[] exceptions) if (!name.equals(methodToVisit.getName()) || !desc.equals(methodToVisit.getDesc())) { return null ; } if (passthroughDataflowMethodVisitor != null ) { throw new IllegalStateException("Constructing passthroughDataflowMethodVisitor twice!" ); } MethodVisitor mv = super .visitMethod(access, name, desc, signature, exceptions); passthroughDataflowMethodVisitor = new PassthroughDataflowMethodVisitor( classMap, inheritanceMap, this .passthroughDataflow, serializableDecider, api, mv, this .name, access, name, desc, signature, exceptions); return new JSRInlinerAdapter(passthroughDataflowMethodVisitor, access, name, desc, signature, exceptions); }
前面是一些筛选工作,只挑出当前指定method进行观察。然后对method进行了PassthroughDataflowMethodVisitor的观察模式。这里面的逻辑也就是比较重点的一部分。
这里要注意到PassthroughDataflowMethodVisitor继承的是TaintTrackingMethodVisitor类
下面的操作涉及到很多字节码、JVM指令相关,很多东西也不太了解,就只能稍微讲解下我的理解。
TaintTrackingMethodVisitor中定义了一个全局变量PASSTHROUGH_DATAFLOW,个人理解应该就是propagator也就是污点传播函数。哪些函数的参数传入会传播污点信息,这里主要就是做了这样一个标记。
一些栈帧操作先跳过不看(因为具体我也不太了解),可以重点关注下visitMethodInsn这个对函数内部访问时调用的函数。
一开始应该是对静态调用函数的判断,进而做一些操作,因为静态函数的参数0不是this。
1 2 3 4 5 6 7 Type[] argTypes = Type.getArgumentTypes(desc); if (opcode != Opcodes.INVOKESTATIC) { Type[] extendedArgTypes = new Type[argTypes.length+1 ]; System.arraycopy(argTypes, 0 , extendedArgTypes, 1 , argTypes.length); extendedArgTypes[0 ] = Type.getObjectType(owner); argTypes = extendedArgTypes; }
后面switch的部分才是重点
可以看到对四种invoke方法都做了同一个操作,对JVM函数操作熟悉点的就可以知道这里应该漏了一个动态调用invokedynamic,这也是在项目的介绍中介绍了为什么对一些动态调用操作无法检查的原因。
一开始构造了污染参数的集合,然后通过一些方式来判断污点的传播性。
如果是构造方法,则污染生成的对象
对java/io/ObjectInputStream的defaultReadObject做了特殊处理,污染thiss
如果是内置的propagator函数,则根据定义的参数index来判断是否可污染
根据之前拓扑信息排序,可以直接获取被调用函数的污点传播信息
如果不是静态调用 && 第一个参数是object && 是集合类型(继承了java/util/Collection或者java/util/Map)的,则污染所有的存储元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 switch (opcode) { case Opcodes.INVOKESTATIC: case Opcodes.INVOKEVIRTUAL: case Opcodes.INVOKESPECIAL: case Opcodes.INVOKEINTERFACE: final List<Set<T>> argTaint = new ArrayList<Set<T>>(argTypes.length); for (int i = 0 ; i < argTypes.length; i++) { argTaint.add(null ); } for (int i = 0 ; i < argTypes.length; i++) { Type argType = argTypes[i]; if (argType.getSize() > 0 ) { for (int j = 0 ; j < argType.getSize() - 1 ; j++) { pop(); } argTaint.set(argTypes.length - 1 - i, pop()); } } Set<T> resultTaint; if (name.equals("<init>" )) { resultTaint = argTaint.get(0 ); } else { resultTaint = new HashSet<>(); } if (owner.equals("java/io/ObjectInputStream" ) && name.equals("defaultReadObject" ) && desc.equals("()V" )) { savedVariableState.localVars.get(0 ).addAll(argTaint.get(0 )); } for (Object[] passthrough : PASSTHROUGH_DATAFLOW) { if (passthrough[0 ].equals(owner) && passthrough[1 ].equals(name) && passthrough[2 ].equals(desc)) { for (int i = 3 ; i < passthrough.length; i++) { resultTaint.addAll(argTaint.get((Integer)passthrough[i])); } } } if (passthroughDataflow != null ) { Set<Integer> passthroughArgs = passthroughDataflow.get(methodHandle); if (passthroughArgs != null ) { for (int arg : passthroughArgs) { resultTaint.addAll(argTaint.get(arg)); } } } if (opcode != Opcodes.INVOKESTATIC && argTypes[0 ].getSort() == Type.OBJECT) { Set<ClassReference.Handle> parents = inheritanceMap.getSuperClasses(new ClassReference.Handle(argTypes[0 ].getClassName().replace('.' , '/' ))); if (parents != null && (parents.contains(new ClassReference.Handle("java/util/Collection" )) || parents.contains(new ClassReference.Handle("java/util/Map" )))) { for (int i = 1 ; i < argTaint.size(); i++) { argTaint.get(0 ).addAll(argTaint.get(i)); } if (returnType.getSort() == Type.OBJECT || returnType.getSort() == Type.ARRAY) { resultTaint.addAll(argTaint.get(0 )); } } } if (retSize > 0 ) { push(resultTaint); for (int i = 1 ; i < retSize; i++) { push(); } } break ; default : throw new IllegalStateException("Unsupported opcode: " + opcode); }
然后回来看PassthroughDataflowMethodVisitor重载的部分,主要重载了两个函数visitFieldInsn和visitMethodInsn
其中做的操作个人看不出太多原委,涉及到很多堆栈之类的,才疏学浅,不过推荐看 https://xz.aliyun.com/t/7058#toc-3 部分的分析,感觉讲的很不错。
通过PassthroughDataflowMethodVisitor就可以获取到所有方法的以及对应污染返回值的参数index信息
save 也就是按照特定的格式,将passthroughDataflow中的信息保存至passthrough.dat中
1 2 3 4 5 6 7 public void save () throws IOException if (passthroughDataflow == null ) { throw new IllegalStateException("Save called before discover()" ); } DataLoader.saveData(Paths.get("passthrough.dat" ), new PassThroughFactory(), passthroughDataflow.entrySet()); }
个人感觉这部分信息应该是污点分析中最重要的一部分信息了,所以中间的处理过程也相对比较复杂类名 | 方法名 | 方法描述 | 污点index
CallGraphDiscovery 这里主要是获取各个函数之间的调用关系(Call Graph),以及调用者与被调用函数之间参数的传递关系
discover 一开始还是一样的load之前加载过的信息
1 2 3 4 5 6 7 8 Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods(); Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses(); InheritanceMap inheritanceMap = InheritanceMap.load(); Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = PassthroughDiscovery.load();
然后通过ModelGeneratorClassVisitor来进行类观察,这时候可以注意到多传入了一个serializableDecider序列化决策者,它是一个接口,每个config都有对应的具体实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 SerializableDecider serializableDecider = config.getSerializableDecider(methodMap, inheritanceMap); for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) { try (InputStream in = classResource.getInputStream()) { ClassReader cr = new ClassReader(in); try { cr.accept(new ModelGeneratorClassVisitor(classMap, inheritanceMap, passthroughDataflow, serializableDecider, Opcodes.ASM6), ClassReader.EXPAND_FRAMES); } catch (Exception e) { LOGGER.error("Error analyzing: " + classResource.getName(), e); } } }
ModelGeneratorClassVisitor一开始是简单的记录对应信息,然后在visitMethod时用ModelGeneratorMethodVisitor对方法进行观察
1 2 3 4 5 6 7 @Override public MethodVisitor visitMethod (int access, String name, String desc, String signature, String[] exceptions) MethodVisitor mv = super .visitMethod(access, name, desc, signature, exceptions); ModelGeneratorMethodVisitor modelGeneratorMethodVisitor = new ModelGeneratorMethodVisitor(classMap, inheritanceMap, passthroughDataflow, serializableDecider, api, mv, this .name, access, name, desc, signature, exceptions); return new JSRInlinerAdapter(modelGeneratorMethodVisitor, access, name, desc, signature, exceptions); }
ModelGeneratorMethodVisitor主要重写了visitCode、visitFieldInsn、visitMethodInsn三个方法
具体入栈出栈规则确实也能力有限,推荐看 https://xz.aliyun.com/t/7058#toc-4
从而获取到调用函数与被调用函数的参数对应关系
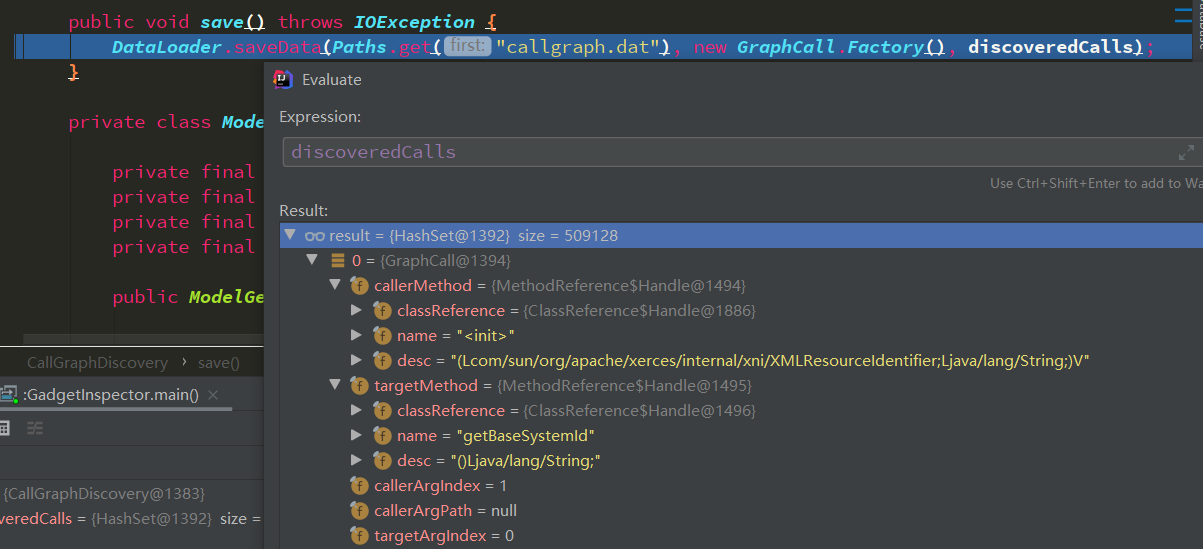
save save的方式也和之前类似,将获取到的discoveredCalls变量以特定格式存储到callgraph.dat中
存储的格式为
1 2 调用者类名 | 调用者方法 | 调用者方法描述 | 被调用者类名 | 被调用者方法 | 被调用者方法描述 | 调用者方法参index | 调用者字段名 | 被调用者方法参数索引 Main (Ljava/lang/String;)V main A method1 (Ljava/lang/String;)Ljava/lang/String; 1 1
SourceDiscovery 这里的功能就是找到所有的source点
1 2 3 4 5 6 7 if (!Files.exists(Paths.get("sources.dat" ))) { LOGGER.info("Discovering gadget chain source methods..." ); SourceDiscovery sourceDiscovery = config.getSourceDiscovery(); sourceDiscovery.discover(); sourceDiscovery.save(); }
这里的SourceDiscovery是个抽象类,会根据config有具体的实现,后面的部分就以jackson的实现为具体例子
discover 最开始的discover入口在抽象类中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses(); Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods(); InheritanceMap inheritanceMap = InheritanceMap.load(); Map<MethodReference.Handle, Set<GraphCall>> graphCallMap = new HashMap<>(); for (GraphCall graphCall : DataLoader.loadData(Paths.get("callgraph.dat" ), new GraphCall.Factory())) { MethodReference.Handle caller = graphCall.getCallerMethod(); if (!graphCallMap.containsKey(caller)) { Set<GraphCall> graphCalls = new HashSet<>(); graphCalls.add(graphCall); graphCallMap.put(caller, graphCalls); } else { graphCallMap.get(caller).add(graphCall); } } discover(classMap, methodMap, inheritanceMap, graphCallMap);
load了类信息/函数信息/继承信息
然后根据graphCall中的信息,生成了graphCallMap,也就是caller -> set(GraphCall)的信息,然后一同传入实现类的discover方法中
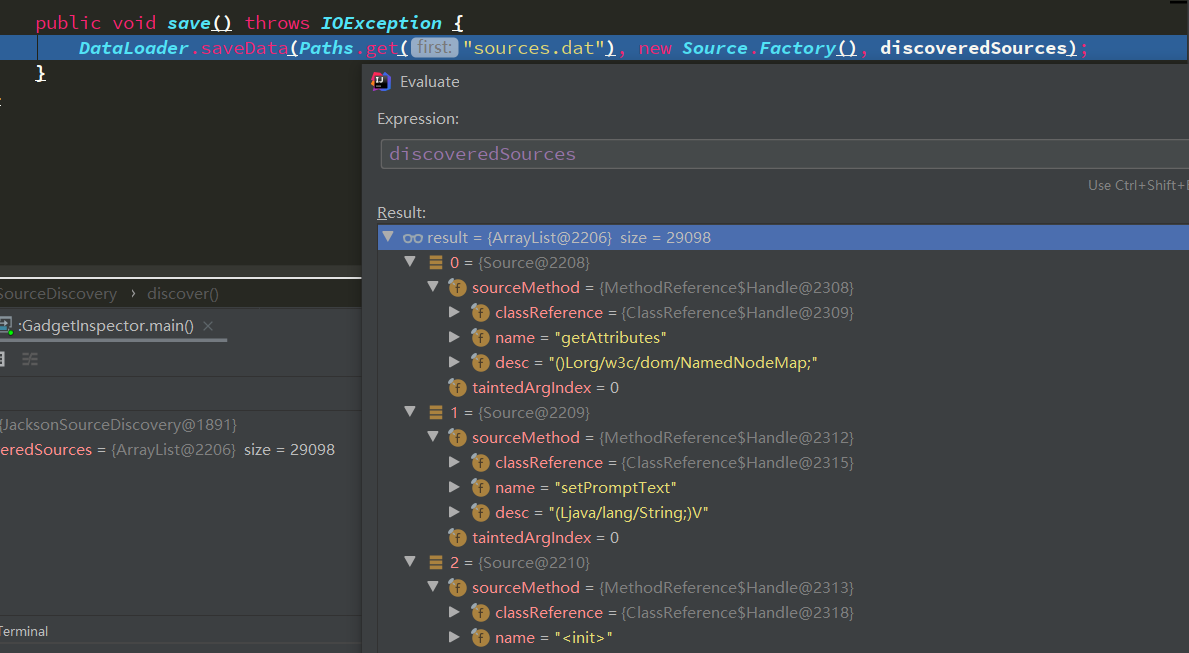
以jackson的实现类为例,可以看到这里将所有的初始化方法,getter和setter方法都设为了source。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 final JacksonSerializableDecider serializableDecider = new JacksonSerializableDecider(methodMap);for (MethodReference.Handle method : methodMap.keySet()) { if (serializableDecider.apply(method.getClassReference())) { if (method.getName().equals("<init>" ) && method.getDesc().equals("()V" )) { addDiscoveredSource(new Source(method, 0 )); } if (method.getName().startsWith("get" ) && method.getDesc().startsWith("()" )) { addDiscoveredSource(new Source(method, 0 )); } if (method.getName().startsWith("set" ) && method.getDesc().matches("\\(L[^;]*;\\)V" )) { addDiscoveredSource(new Source(method, 0 )); } } }
这样就获取到了所有的source点
save 然后就是将source信息保存到sources.bat中
可以看到Source类中不仅记录了方法信息,还有被污染的参数index(当然索引信息对jackson来说应该是用不上的)
GadgetChainDiscovery 前面都是信息搜集的工作,到这里就是真正的gadget寻找过程了
while前面都是一些准备工作
获取method信息和类继承关系,并获取所有method的继承/实现关系,并保存到methodimpl.dat中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods(); InheritanceMap inheritanceMap = InheritanceMap.load(); Map<MethodReference.Handle, Set<MethodReference.Handle>> methodImplMap = InheritanceDeriver.getAllMethodImplementations( inheritanceMap, methodMap); final ImplementationFinder implementationFinder = config.getImplementationFinder( methodMap, methodImplMap, inheritanceMap); try (Writer writer = Files.newBufferedWriter(Paths.get("methodimpl.dat" ))) { for (Map.Entry<MethodReference.Handle, Set<MethodReference.Handle>> entry : methodImplMap.entrySet()) { writer.write(entry.getKey().getClassReference().getName()); writer.write("\t" ); writer.write(entry.getKey().getName()); writer.write("\t" ); writer.write(entry.getKey().getDesc()); writer.write("\n" ); for (MethodReference.Handle method : entry.getValue()) { writer.write("\t" ); writer.write(method.getClassReference().getName()); writer.write("\t" ); writer.write(method.getName()); writer.write("\t" ); writer.write(method.getDesc()); writer.write("\n" ); } } }
后面是load callgraph,并和之前一样整理到grapCallMap信息
然后加载source信息,初始化gadgetChain(需要注意一下的是GadgetChainLink应该指的是一个node节点,GadgetChain指的是整条gadget链)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Map<MethodReference.Handle, Set<GraphCall>> graphCallMap = new HashMap<>(); for (GraphCall graphCall : DataLoader.loadData(Paths.get("callgraph.dat" ), new GraphCall.Factory())) { MethodReference.Handle caller = graphCall.getCallerMethod(); if (!graphCallMap.containsKey(caller)) { Set<GraphCall> graphCalls = new HashSet<>(); graphCalls.add(graphCall); graphCallMap.put(caller, graphCalls); } else { graphCallMap.get(caller).add(graphCall); } } Set<GadgetChainLink> exploredMethods = new HashSet<>(); LinkedList<GadgetChain> methodsToExplore = new LinkedList<>(); LinkedList<GadgetChain> methodsToExploreRepeat = new LinkedList<>(); for (Source source : DataLoader.loadData(Paths.get("sources.dat" ), new Source.Factory())) { GadgetChainLink srcLink = new GadgetChainLink(source.getSourceMethod(), source.getTaintedArgIndex()); if (exploredMethods.contains(srcLink)) { continue ; } methodsToExplore.add(new GadgetChain(Arrays.asList(srcLink))); exploredMethods.add(srcLink); }
while中的部分就是真正开始找链的部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 while (methodsToExplore.size() > 0 ) { if ((iteration % 1000 ) == 0 ) { LOGGER.info("Iteration " + iteration + ", Search space: " + methodsToExplore.size()); } iteration += 1 ; GadgetChain chain = methodsToExplore.pop(); GadgetChainLink lastLink = chain.links.get(chain.links.size()-1 ); Set<GraphCall> methodCalls = graphCallMap.get(lastLink.method); if (methodCalls != null ) { for (GraphCall graphCall : methodCalls) { if (graphCall.getCallerArgIndex() != lastLink.taintedArgIndex) { continue ; } Set<MethodReference.Handle> allImpls = implementationFinder.getImplementations(graphCall.getTargetMethod()); for (MethodReference.Handle methodImpl : allImpls) { GadgetChainLink newLink = new GadgetChainLink(methodImpl, graphCall.getTargetArgIndex()); if (exploredMethods.contains(newLink)) { if (chain.links.size() < 2 ) { GadgetChain newChain = new GadgetChain(chain, newLink); methodsToExploreRepeat.add(newChain); } continue ; } GadgetChain newChain = new GadgetChain(chain, newLink); if (isSink(methodImpl, graphCall.getTargetArgIndex(), inheritanceMap)) { discoveredGadgets.add(newChain); } else { methodsToExplore.add(newChain); exploredMethods.add(newLink); } } } } }
用while循环的目的是因为在寻找的过程中,如果没到达sink,则会将新延长的gadget加入其中,后续继续寻找更长的链(除非改链无法继续延长了,也就是没有多余的CallGraph)
去出带寻找的链,pop出最后一个节点,并获取最后一个节点的所有函数调用(GraphCall)
1 2 3 GadgetChain chain = methodsToExplore.pop(); GadgetChainLink lastLink = chain.links.get(chain.links.size()-1 ); Set<GraphCall> methodCalls = graphCallMap.get(lastLink.method);
遍历所有的GraphCall
1 for (GraphCall graphCall : methodCalls)
如果可控参数位置不对应,则跳过
1 2 3 if (graphCall.getCallerArgIndex() != lastLink.taintedArgIndex) { continue ; }
之后获取所有的实现方法(但对应不同的config有不同的实现,例如jackson获取的就不是所有实现方法)
具体逻辑可以跟进到JacksonImplementationFinder的apply
1 2 3 4 5 6 7 8 9 10 11 12 @Override public Set<MethodReference.Handle> getImplementations(MethodReference.Handle target) { Set<MethodReference.Handle> allImpls = new HashSet<>(); if (Boolean.TRUE.equals(serializableDecider.apply(target.getClassReference()))) { allImpls.add(target); } return allImpls; }
JacksonSerializableDecider的apply
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Override public Boolean apply (ClassReference.Handle handle) Boolean cached = cache.get(handle); if (cached != null ) { return cached; } Set<MethodReference.Handle> classMethods = methodsByClassMap.get(handle); if (classMethods != null ) { for (MethodReference.Handle method : classMethods) { if (method.getName().equals("<init>" ) && method.getDesc().equals("()V" )) { cache.put(handle, Boolean.TRUE); return Boolean.TRUE; } } } cache.put(handle, Boolean.FALSE); return Boolean.FALSE; }
可以看到作者也解释了对于jackson来说只要有构造方法则通过决策,返回当前类。(为啥没有父类?)
而javaserial的getImplementations中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Override public Set<MethodReference.Handle> getImplementations(MethodReference.Handle target) { Set<MethodReference.Handle> allImpls = new HashSet<>(); allImpls.add(target); Set<MethodReference.Handle> subClassImpls = methodImplMap.get(target); if (subClassImpls != null ) { for (MethodReference.Handle subClassImpl : subClassImpls) { if (Boolean.TRUE.equals(serializableDecider.apply(subClassImpl.getClassReference()))) { allImpls.add(subClassImpl); } } } return allImpls; }
1 2 3 4 5 6 7 8 9 10 @Override public Boolean apply (ClassReference.Handle handle) Boolean cached = cache.get(handle); if (cached != null ) { return cached; } Boolean result = applyNoCache(handle); cache.put(handle, result); return result; }
1 2 3 4 5 6 7 8 9 10 private Boolean applyNoCache (ClassReference.Handle handle) if (isBlacklistedClass(handle)) { return false ; } if (inheritanceMap.isSubclassOf(handle, new ClassReference.Handle("java/io/Serializable" ))) { return true ; } return false ; }
主要就是判断包括当前类在内的所有父类/实现类是否实现了Serializable(也就是是否可实例化),然后将包括当前方法在内的实现方法返回。
然后对于所有符合要求的methodImpl进行遍历
判断是否被访问过的节点,避免死循环
其实个人感觉这里判断的方式其实有点问题,单纯的用exploredMethods.contains来判断总感觉不大合理,总感觉是应该判断gadget的链路上是否包含newLink
1 2 3 4 5 6 7 8 GadgetChainLink newLink = new GadgetChainLink(methodImpl, graphCall.getTargetArgIndex()); if (exploredMethods.contains(newLink)) { if (chain.links.size() < 2 ) { GadgetChain newChain = new GadgetChain(chain, newLink); methodsToExploreRepeat.add(newChain); } continue ; }
然后判断是否到达了sink点,到了则加入discoveredGadgets中,否则相当于延长了链路,则添加到exploredMethods中,等待下一次寻找新的延申节点
1 2 3 4 5 6 7 8 9 GadgetChain newChain = new GadgetChain(chain, newLink); if (isSink(methodImpl, graphCall.getTargetArgIndex(), inheritanceMap)) { discoveredGadgets.add(newChain); } else { methodsToExplore.add(newChain); exploredMethods.add(newLink); }
具体的判断是否是Sink的函数也可以跟进看下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 private boolean isSink (MethodReference.Handle method, int argIndex, InheritanceMap inheritanceMap) if (GadgetInspector.giConfig.getName().equals("sqlinject" )) { return isSQLInjectSink(method, argIndex, inheritanceMap); } if (method.getClassReference().getName().equals("java/io/FileInputStream" ) && method.getName().equals("<init>" )) { return true ; } if (method.getClassReference().getName().equals("java/io/FileOutputStream" ) && method.getName().equals("<init>" )) { return true ; } if (method.getClassReference().getName().equals("java/nio/file/Files" ) && (method.getName().equals("newInputStream" ) || method.getName().equals("newOutputStream" ) || method.getName().equals("newBufferedReader" ) || method.getName().equals("newBufferedWriter" ))) { return true ; } if (method.getClassReference().getName().equals("java/lang/Runtime" ) && method.getName().equals("exec" )) { return true ; } if (method.getClassReference().getName().equals("java/lang/reflect/Method" ) && method.getName().equals("invoke" ) && argIndex == 0 ) { return true ; } if (method.getClassReference().getName().equals("java/net/URLClassLoader" ) && method.getName().equals("newInstance" )) { return true ; } if (method.getClassReference().getName().equals("java/lang/System" ) && method.getName().equals("exit" )) { return true ; } if (method.getClassReference().getName().equals("java/lang/Shutdown" ) && method.getName().equals("exit" )) { return true ; } if (method.getClassReference().getName().equals("java/lang/Runtime" ) && method.getName().equals("exit" )) { return true ; } if (method.getClassReference().getName().equals("java/nio/file/Files" ) && method.getName().equals("newOutputStream" )) { return true ; } if (method.getClassReference().getName().equals("java/lang/ProcessBuilder" ) && method.getName().equals("<init>" ) && argIndex > 0 ) { return true ; } if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("java/lang/ClassLoader" )) && method.getName().equals("<init>" )) { return true ; } if (method.getClassReference().getName().equals("java/net/URL" ) && method.getName().equals("openStream" )) { return true ; } if (method.getClassReference().getName().equals("org/codehaus/groovy/runtime/InvokerHelper" ) && method.getName().equals("invokeMethod" ) && argIndex == 1 ) { return true ; } if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/MetaClass" )) && Arrays.asList("invokeMethod" , "invokeConstructor" , "invokeStaticMethod" ).contains(method.getName())) { return true ; } if ((inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("java/rmi/registry/Registry" )) || inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("javax/naming/Context" ))) && method.getName().equals("lookup" )) { return true ; } return false ; }
一种不太优雅的白名单方式来判断sink。
然后不断地遍历,直至所有未到sink的gadget没有非重复延伸节点为止(通俗说也就是遍历完了所有可能的路径)
一些思考 gadgetinspector的分析是建立在ASM级别的字节码操作上的,对于新人来说其实有些不友好,需要比较多的Java字节码和内存结构的一些知识,相较Soot而言,Soot提供了一种更高层次的抽象,操作起来其实会很舒服(但由于更新不及时对于一些新版本的字节码解析能力差得一批,而且可扩展性自然也没ASM那么好)
由于字节码操作部分的不是很熟悉,具体的操作流程也没有太仔细看,但是貌似加入了控制流图之类的操作(这样的话会比我想象的做的工作要多很多)。至于一些操作上的内存浪费,无缓存,重复工作之类小槽点也不吐槽了,还有一些查找策略的小问题,会导致有一些漏报,在搜索时候的避免死循环的决策导致的,个人感觉那里的判断应该改为if (chain.links.contains(newLink)),只要判断当前链上是否有过改节点即可。还有jackson没扫描实现方法的问题。seebug那篇中说还有callgraph生成不完全的问题,不知道是不是因为控制流之类的原因,具体的实现过程我也没仔细跟了。
总体评价这个程序的话个人感觉学习的意义大于实战的,由于是基于数据流的,一些污点传递函数就需要不断拓展,否则污点信息会比较容跟丢,这就让我想到了去年下半年在freebuf上看到的基于抽象语法树的gadget寻找工具 https://www.freebuf.com/articles/web/213327.html 里面做的工作其实很少,只是单纯的对sink点进行暴力搜索,没有什么实现类的处理和数据流的分析(个人之前自己做的时候发现实现类这种东西确实蛮重要的,尤其是interface,不找到实现类,这个接口是毫无意义的),但是反观下来,这里挖掘的gadget似乎效果更佳明显,编码工作量也没那么大,加一些人工操作之后感觉会更适合实际挖掘。
总之对于实现继承类的处理,和拓扑排序之类的操作确实是可以学习和借鉴的。对于一些自动化审计的工作有一些参考意义。
References https://xz.aliyun.com/t/7058
https://paper.seebug.org/1034/
https://github.com/JackOfMostTrades/gadgetinspector
https://github.com/threedr3am/gadgetinspector
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651750626&idx=1&sn=3e1ac6c41d6e1803abb32285daf0244a&chksm=bd1259af8a65d0b97809a6a8ff5afaff1be4a4232bd8527ef9d95bb7a2e768bd7d9fdc768211&scene=27#wechat_redirect