前言
感觉又是一对web狗极度不友好的比赛,一开始网络环境都是奔溃的,正紧能做题已经是最后两个半小时了。第二道题还是最后一个半小时放出来的,相当难受了。(i春秋真的可以升级下服务器了。。。
不过spider这道反日爬虫的题目感觉还是很有意思的,加上最近刚学的xss和redis,决定还是好好复现一下
spider
题目给了提示说是动态爬虫,一开始对这个不是很了解,大意应该就是自带js解析,类似于浏览器会自动加载js,然后再抓取里面的内容。毕竟这年头ajax那么流行,只抓纯html页面怕是没什么内容。
可以写一个简单的测试样例
1 | <a id="a">123</a> |
将这个html上传之后,可以看到获取到a标签内部的元素变成了test
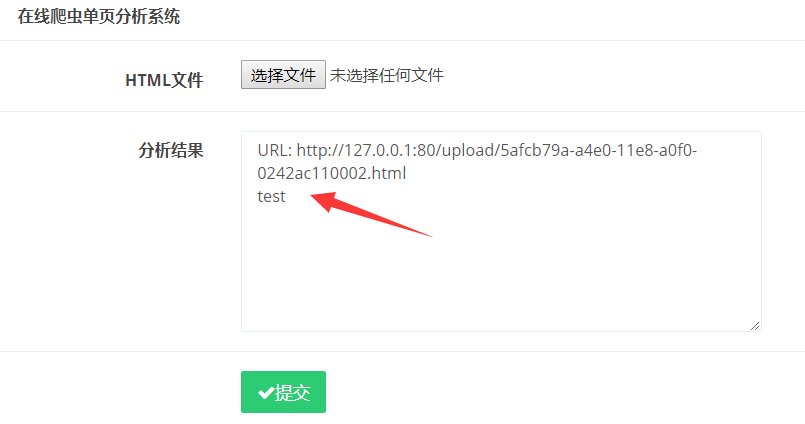
这样一来,就可以利用ajax请求,形成ssrf
由于robots.txt里面有个/get_sourcecode的提示,但是直接访问的时候会显示只能从127.0.0.1访问
于是就先利用爬虫获取下这个页面
1 | <a id="a">123</a> |
这样一来就获取到了源码
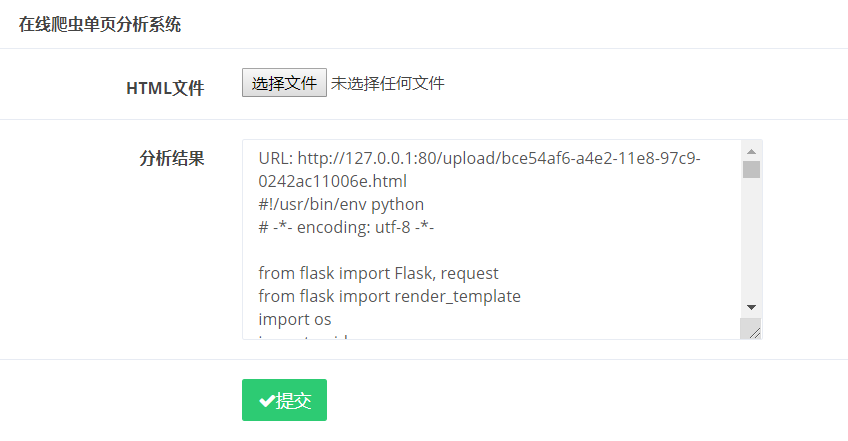
(吐槽一下,那时候和队友就差不多做到这里,由于加了个btoa,然后返回的页面中有中文,就一直返回NULL,相当的难受了
源码里面的逻辑感觉没什么好看的,主要就是一小段
1 | #hint |
就是在html文本中加入level=low_273eac1c就可以绕过恶意关键字的检测
题目也有提示redis,接下来就是利用这个ssrf来攻击redis了
这里有两个小trick
- redis是简单的数据流格式,以一行数据当作一条命令执行
- 同源策略是浏览器对对方返回的数据进行了拦截,但请求实际已经发出
这样,就可以利用ajax传送一个post数据给127.0.0.1:6379,从而盲打redis
提示中8000端口存在apache,于是接下来就利用redis往/var/www/html中写入webshell
为了能让我们的数据有回显,需要加上header('Access-Control-Allow-Origin:*')来防止同源策略阻止数据包的返回
1 | level=low_273eac1c |
然后读取flag.php
1 | <a id='test'>123</a> |
就可以获取到flag了
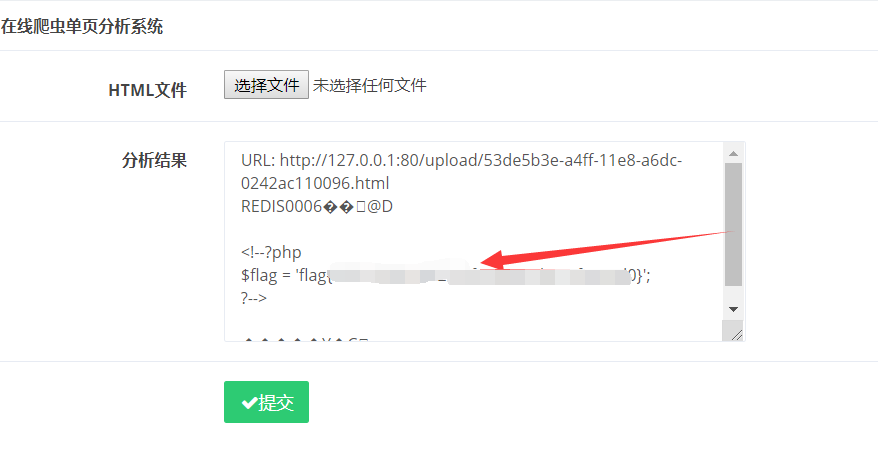
自己后期在本地分析的时候,自己构造的数据包在本地可以成功,然而在比赛环境中总是写入不了shell,就很苦恼。折磨了好久,就暂时先放会把,后续有空再慢慢研究
总而言之感觉这道题的思路还是很巧妙的,而且怎么感觉最近redis的题目有点多哈。。
fakebook
一开始扫出了flag.php和user.php.bak
由于注册时会自动访问你的博客内容,我和队友一致认为是ssrf任意文件读取
何况user.php.bak中还给了防御的正则,于是就把精力放在了绕正则上
最后比完老哥们说是到注入==、,其实一开始是有发现view.php会报错,但是没往注入想
然后几乎约等于没过滤,不能用union就用报错,(感觉自己动不动就盲注的习惯要改改了,第一反应都是盲注
然后payload什么的也很简单
1 | http://837d5d8ffa2f44df8d886d0ce5324565b6dd49a0904e40c7.game.ichunqiu.com/view.php |
数据库里找不到flag,后来想想是不是要新增一条blog=file:///var/www/html/flag.php的用户,但是好像没找到insert或者update注入的点
等下师傅们writeup把。。
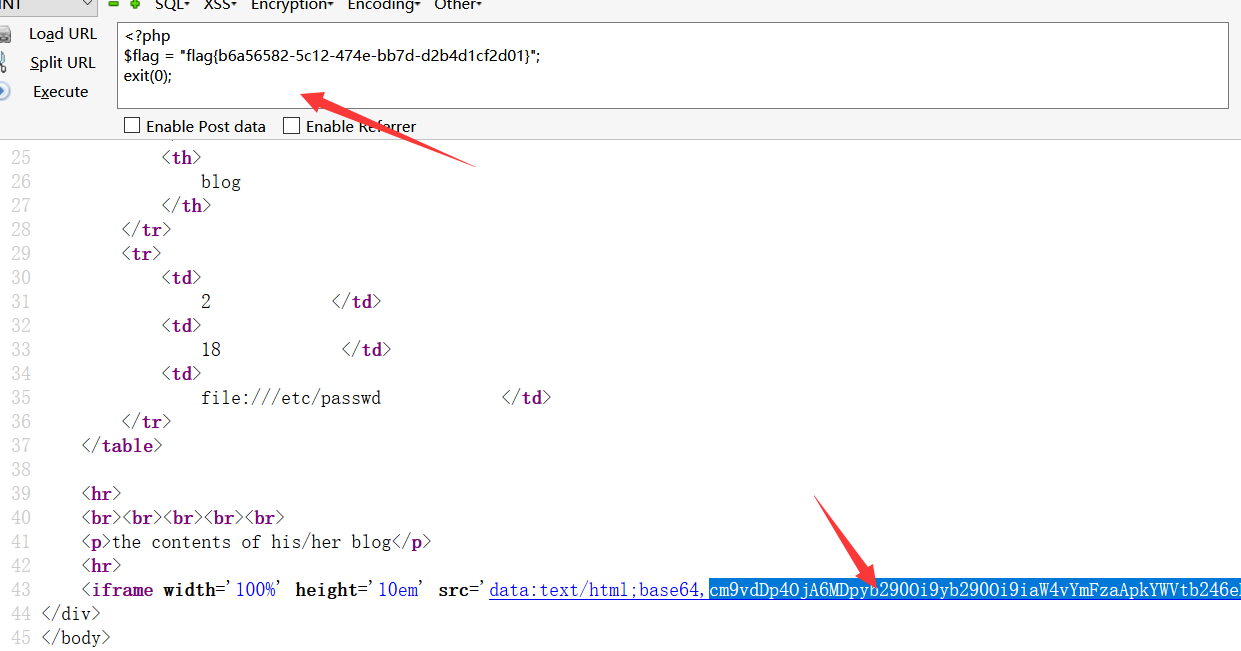
好吧,看完了writeup 原来可以用/**/的方式绕过拦截union的waf,这样的话思路就比较清晰了。
payload
1 | http://f37db81cf64d47b6b64c8f50bb032d2abfd66b829a434eae.game.ichunqiu.com/view.php |
就可以进行任意文件的读取了
总结
感觉比赛的时候思路还是比较闭塞,没有打开。而且确实和大佬们有点差距,好好学习去了。。